Databricks, the Data and Artificial Intelligence (AI) company, has announced the launch of DBRX, a general purpose large language model (LLM) that outperforms all established open source models on standard benchmarks.
This new offering democratises the training and tuning of custom, high-performing LLMs for enterprises so they no longer need to rely on a small handful of closed models. Available now, DBRX enables organisations around the world to cost-effectively build, train, and serve their own custom LLMs.
“At Databricks, our vision has always been to democratise data and AI. We’re doing that by delivering data intelligence to every enterprise—helping them understand and use their private data to build their own AI systems. DBRX is the result of that aim,” said Ali Ghodsi, Co-Founder of and CEO at Databricks.
Ghodsi added: “We’re excited about DBRX for three key reasons: First, it beats open source models on state-of-the-art industry benchmarks. Second, it beats GPT-3.5 on most benchmarks, which should accelerate the trend we’re seeing across our customer base as organisations replace proprietary models with open source models. Finally, DBRX uses a mixture-of-experts architecture, making the model extremely fast in terms of tokens per second, as well as being cost effective to serve. All in all, DBRX is setting a new standard for open source LLMs. It gives enterprises a platform to build customized reasoning capabilities based on their own data.”
DBRX Surpasses Open Source Models Across Industry Benchmarks
Databricks’s latest LLM outperforms existing open source LLMs like Llama 2 70B and Mixtral-8x7B on standard industry benchmarks, such as language understanding, programming, math, and logic.
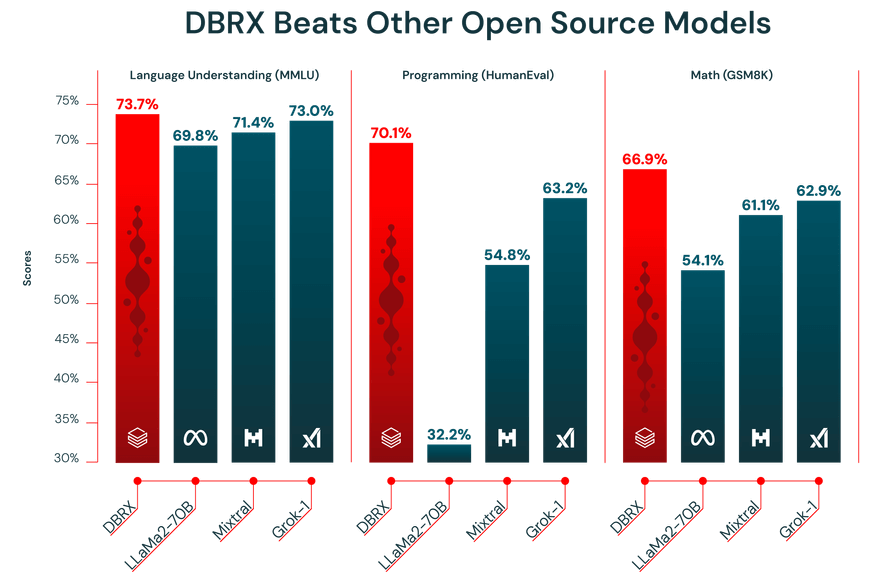
Fig. 1. DBRX outperforms established open source models on language understanding (MMLU), Programming (HumanEval), and Math (GSM8K).
It also outperforms GPT-3.5 on relevant benchmarks.
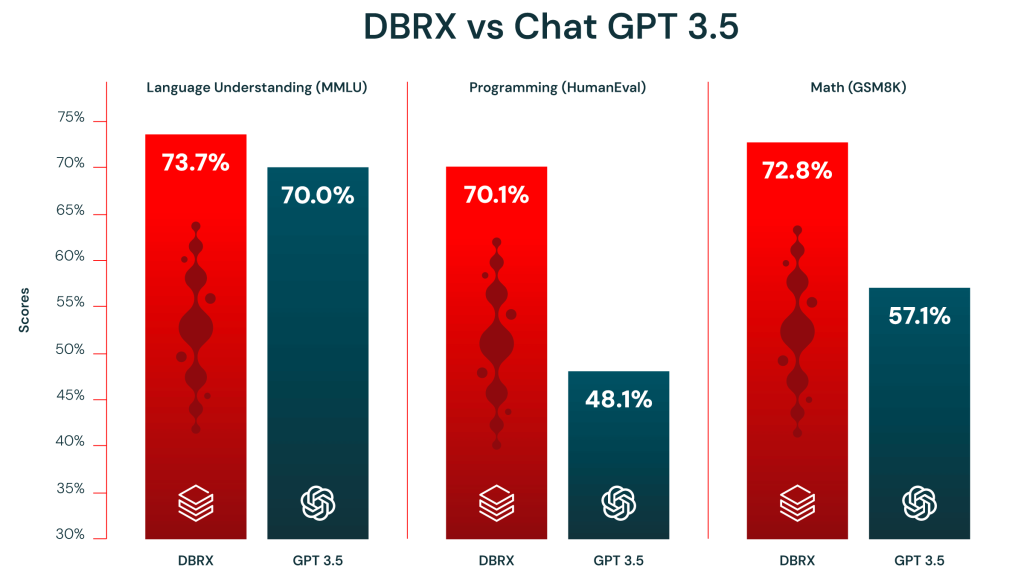
Fig. 2. DBRX outperforms GPT 3.5 across language understanding (MMLU), Programming (HumanEval), and Math (GSM8K).
For an in-depth look at model evaluations and performance benchmarks, and to see how DBRX is competitive with GPT-4 quality for internal use cases such as SQL, visit the Mosaic Research blog.
Setting a New Standard for Efficient Open Source LLMs
DBRX was developed by Mosaic AI and trained on NVIDIA DGX Cloud. Databricks optimised DBRX for efficiency with a mixture-of-experts (MoE) architecture, built on the MegaBlocks open source project. The resulting model has leading performance and is up to twice as compute-efficient as other available leading LLMs.
It set a new standard for open source models, enabling customisable and transparent generative AI for all enterprises. A recent survey from Andreessen Horowitz found that nearly 60 percent of AI leaders are interested in increasing open source usage or switching when fine-tuned open source models roughly match performance of closed source models.
In 2024 and beyond, enterprises expect a significant shift of usage from closed towards open source. Databricks believes DBRX will accelerate this trend.
Paired with Databricks Mosaic AI’s unified tooling, DBRX helps customers rapidly build and deploy production-quality generative AI applications that are safe, accurate, and governed without giving up control of their data and intellectual property. Customers benefit from built-in data management, governance, lineage, and monitoring capabilities on the Databricks Data Intelligence Platform.
Availability
DBRX is freely available on GitHub and Hugging Face for research and commercial use. It is also available on AWS and Google Cloud, as well as directly on Microsoft Azure through Azure Databricks. It is also expected to be available through the NVIDIA API Catalog and supported on the NVIDIA NIM inference microservice.
To learn more, visit the Mosaic AI research blog or join the webinar on the 25th of April at 8:00 a.m. PT.
 (0)
(0) (0)
(0)Archive
- October 2024(44)
- September 2024(94)
- August 2024(100)
- July 2024(99)
- June 2024(126)
- May 2024(155)
- April 2024(123)
- March 2024(112)
- February 2024(109)
- January 2024(95)
- December 2023(56)
- November 2023(86)
- October 2023(97)
- September 2023(89)
- August 2023(101)
- July 2023(104)
- June 2023(113)
- May 2023(103)
- April 2023(93)
- March 2023(129)
- February 2023(77)
- January 2023(91)
- December 2022(90)
- November 2022(125)
- October 2022(117)
- September 2022(137)
- August 2022(119)
- July 2022(99)
- June 2022(128)
- May 2022(112)
- April 2022(108)
- March 2022(121)
- February 2022(93)
- January 2022(110)
- December 2021(92)
- November 2021(107)
- October 2021(101)
- September 2021(81)
- August 2021(74)
- July 2021(78)
- June 2021(92)
- May 2021(67)
- April 2021(79)
- March 2021(79)
- February 2021(58)
- January 2021(55)
- December 2020(56)
- November 2020(59)
- October 2020(78)
- September 2020(72)
- August 2020(64)
- July 2020(71)
- June 2020(74)
- May 2020(50)
- April 2020(71)
- March 2020(71)
- February 2020(58)
- January 2020(62)
- December 2019(57)
- November 2019(64)
- October 2019(25)
- September 2019(24)
- August 2019(14)
- July 2019(23)
- June 2019(54)
- May 2019(82)
- April 2019(76)
- March 2019(71)
- February 2019(67)
- January 2019(75)
- December 2018(44)
- November 2018(47)
- October 2018(74)
- September 2018(54)
- August 2018(61)
- July 2018(72)
- June 2018(62)
- May 2018(62)
- April 2018(73)
- March 2018(76)
- February 2018(8)
- January 2018(7)
- December 2017(6)
- November 2017(8)
- October 2017(3)
- September 2017(4)
- August 2017(4)
- July 2017(2)
- June 2017(5)
- May 2017(6)
- April 2017(11)
- March 2017(8)
- February 2017(16)
- January 2017(10)
- December 2016(12)
- November 2016(20)
- October 2016(7)
- September 2016(102)
- August 2016(168)
- July 2016(141)
- June 2016(149)
- May 2016(117)
- April 2016(59)
- March 2016(85)
- February 2016(153)
- December 2015(150)
