
Salesforce has announced the world’s first LLM benchmark for customer relationship management (CRM) to help businesses evaluate the rapidly growing number of large language models (LLMs) for use in their CRM systems.
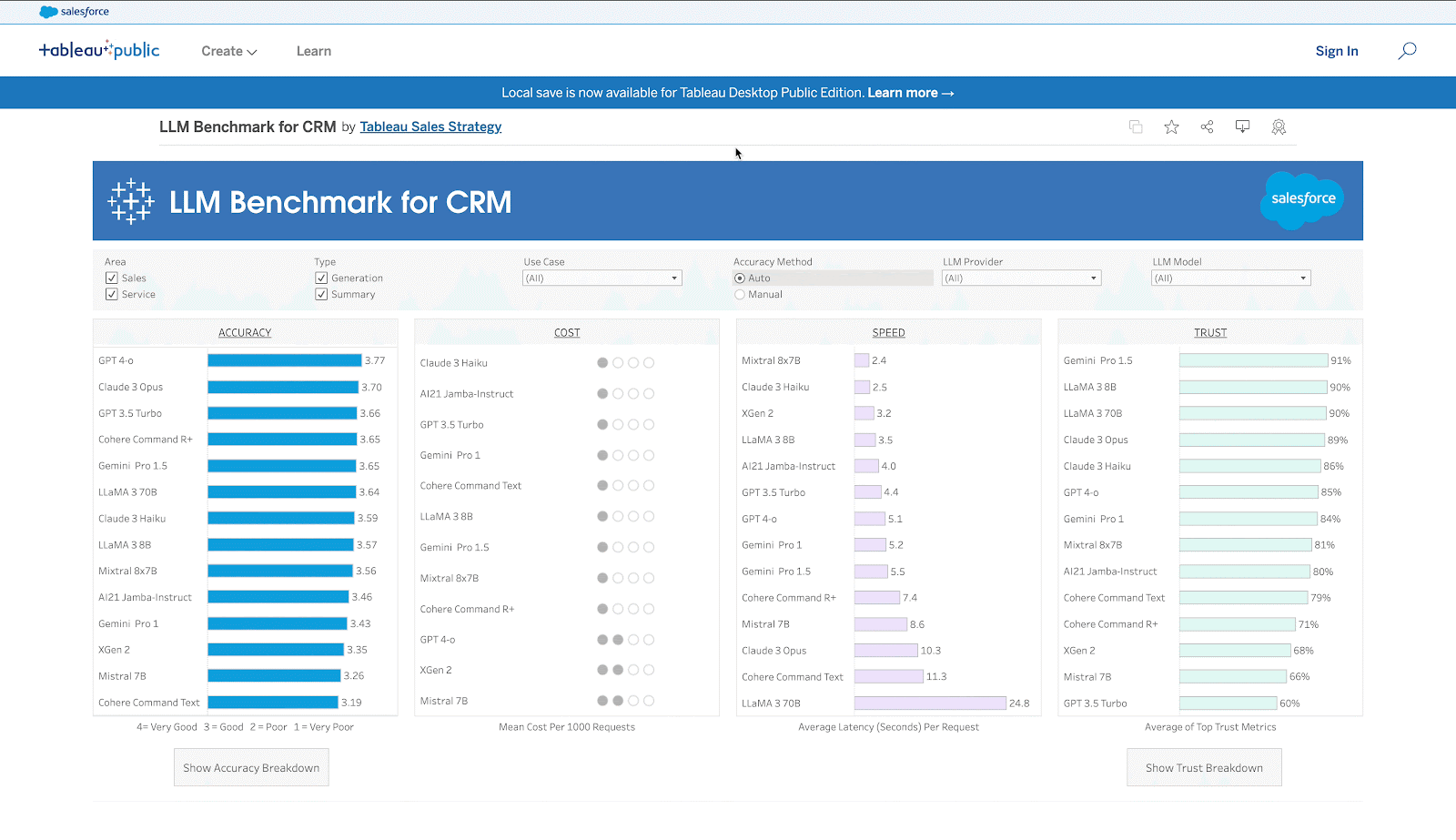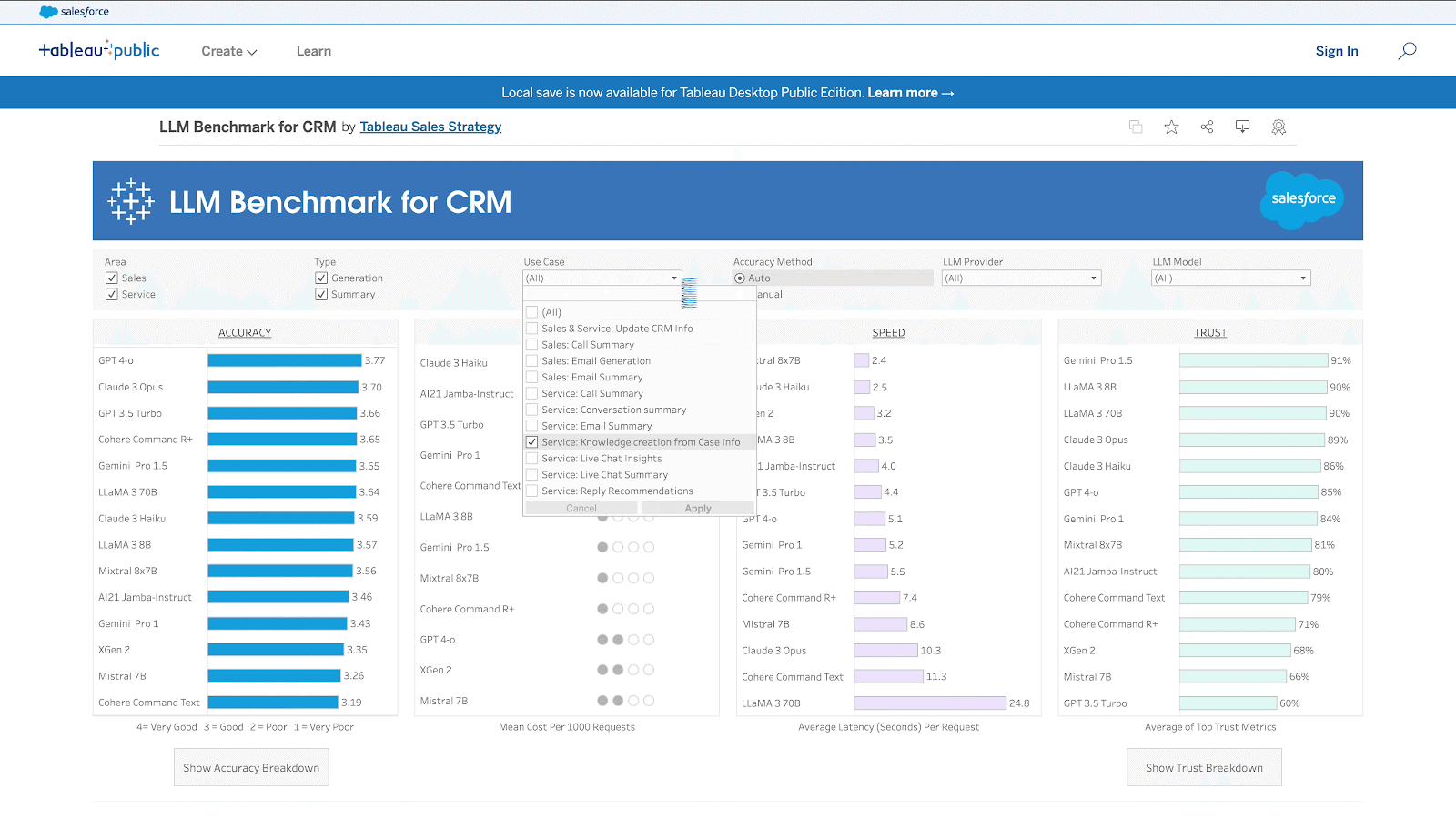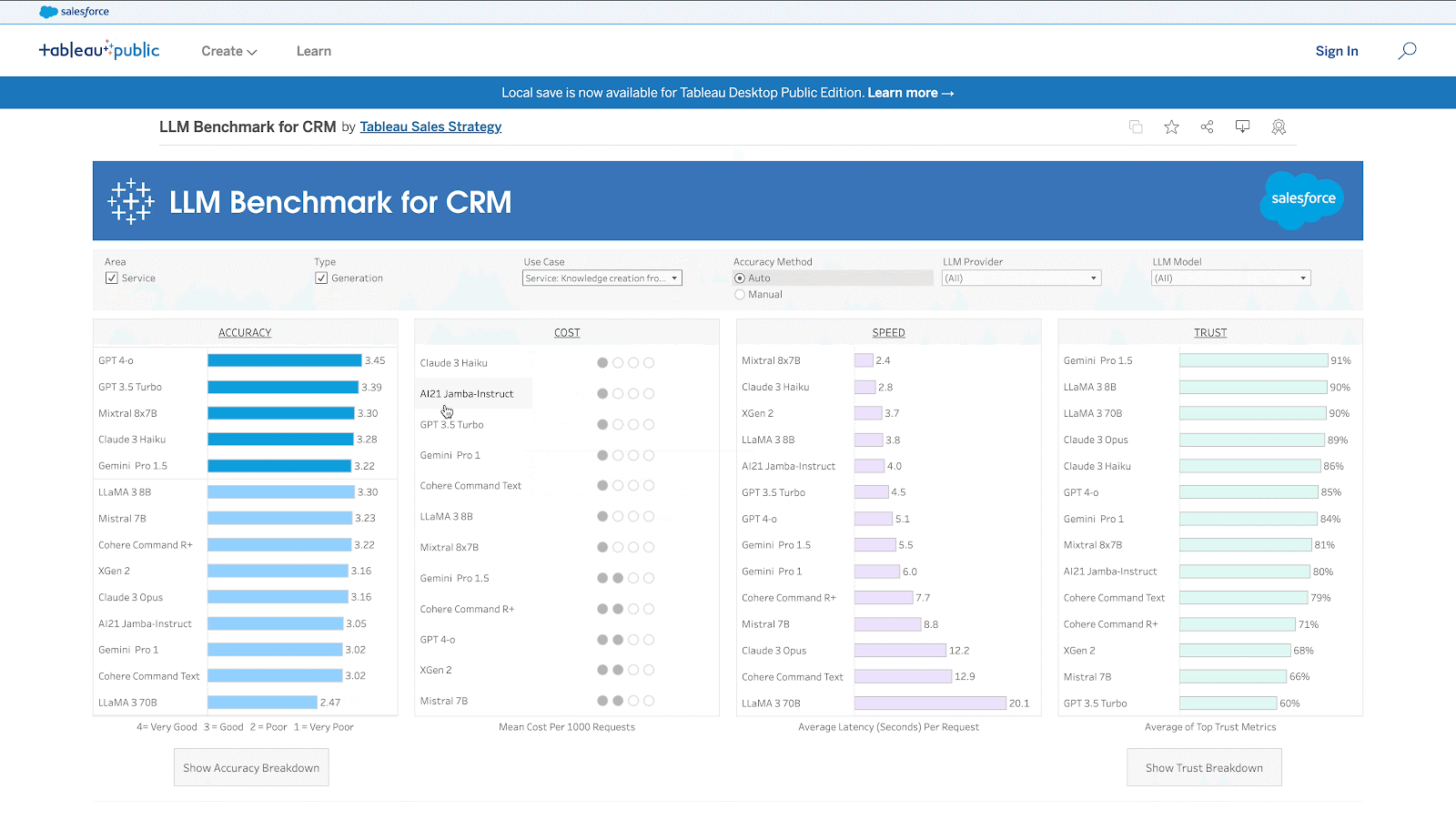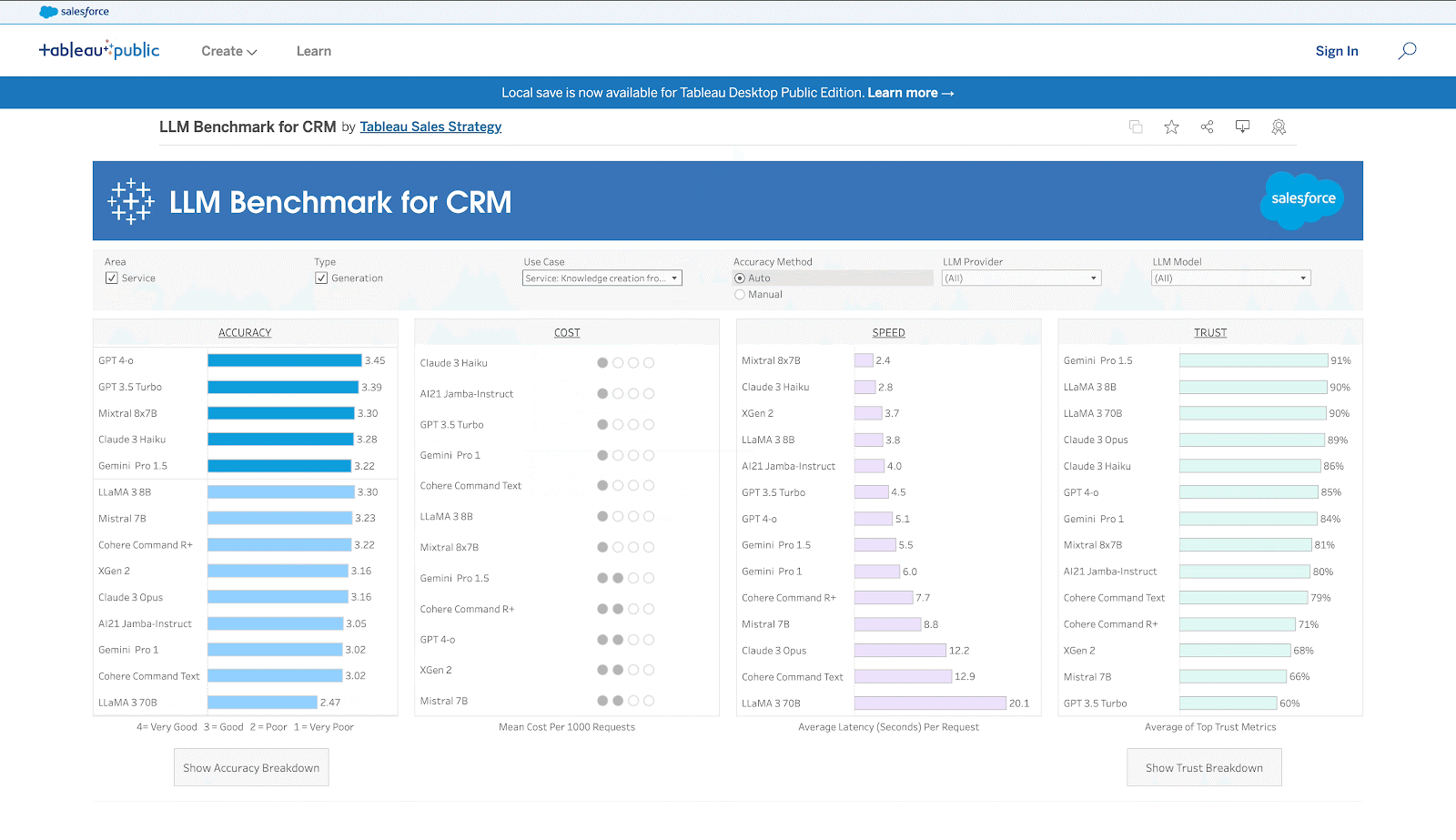
The new benchmark is a comprehensive evaluation framework that measures the performance of LLMs against four key measures: accuracy, cost, speed, and trust and safety. It was specifically designed to evaluate common sales and service use cases, including prospecting, lead nurturing, as well as sales opportunity and service case summaries.
The benchmark also includes a public leaderboard to help professionals decide which LLM is best for their CRM needs. Salesforce will continue to incorporate new use case scenarios into the benchmark and enhance its evaluation of LLMs, which will soon include fine-tuned LLMs.
“As AI continues to evolve, enterprise leaders are saying it’s important to find the right mix of performance, accuracy, responsibility, and cost to unlock the full potential of generative AI to drive business growth,” said Silvio Savarese, EVP & Chief Scientist, Salesforce AI Research.
Savarese added: “Salesforce’s new LLM Benchmark for CRM is a significant step forward in the way businesses assess their AI strategy within the industry. It not only provides clarity on next-generation AI deployment but also can accelerate time to value for CRM-specific use cases. Our commitment is to continuously evolve this benchmark to keep pace with technological advancements, ensuring it remains relevant and valuable.”
Why the Salesforce Benchmark Matters
Existing LLM benchmarks have been limited to academic and consumer use cases, with very little business relevance. They also lack adequate expert human evaluations and fail to address accuracy, speed, cost, and trust considerations. These deficiencies have left CRM customers lacking a reliable way to gauge the effectiveness of generative AI-powered CRM solutions. Without a clear sense of how LLMs perform across those metrics for specific use cases, businesses are left to make decisions in the dark.
Dive Deeper
Developed by Salesforce AI Research, the benchmark uniquely uses real-world CRM data and uniquely makes use of expert human evaluations by practitioners. This enables businesses to use the benchmark to make more strategic decisions about how to incorporate generative AI into their CRM systems, with specific attention to:
- AccuracyThis metric comprises four subcategories: factuality, completeness, conciseness, and instruction-following. The more accurate the predictions or recommendations, the more valuable the results are to teams across the organisation. And the more valuable the results, the better the actions they can take to improve customer experience. If a model is accurate enough for a use case, it is also important to consider the other metrics. Even if the model is not accurate enough, techniques like prompt engineering and fine-tuning can improve it.
- Cost. The cost metric is categorised as high, medium, and low based on percentiles. It is the estimated operational cost that varies by CRM use case. Customers can evaluate the cost-effectiveness of different LLMs to ensure they align with their budget and resource allocation strategies.
- Speed. This metric assesses the LLM’s responsiveness and efficiency in processing and delivering information. Faster response times enhance the user experience, reduce wait times for customers, and enable sales and service teams to address inquiries and issues promptly.
- Trust and Safety. This metric measures the LLM’s capability to shield sensitive customer data, adhere to data privacy regulations, secure information, and refrain from bias and toxicity for CRM use cases. By assessing the reliability of LLMs for CRM, this benchmark gives organisations a sense of transparency regarding trust and safety.
Making Good, Informed Decisions Using First-of-Its-Kind Benchmark
Organisations can use this benchmark to compare LLMs, identify the best solution, and make more informed decisions that will deliver customer success and propel their business forward.
Additionally, with Salesforce’s Einstein 1 Platform, customers can choose from existing LLMs or bring their own models to meet their unique business needs. By selecting models for their CRM use cases using the benchmark, businesses can deploy more effective and efficient generative AI solutions.
“Business organisations are looking to utilise AI to drive growth, cut costs, and deliver personalised customer experiences, not to plan a kid’s birthday party or summarise Othello,” said Clara Shih, CEO of Salesforce AI. “Our customers have been asking for a purpose-built way to evaluate and select from among the proliferation of new AI models, and we are thrilled to introduce the world’s first LLM benchmark for CRM to help them navigate the complex landscape of models. This benchmark is not just a measure; it’s a comprehensive, dynamically evolving framework that empowers companies to make informed decisions, balancing accuracy, cost, speed, and trust.”
 (0)
(0) (0)
(0)Archive
- October 2024(44)
- September 2024(94)
- August 2024(100)
- July 2024(99)
- June 2024(126)
- May 2024(155)
- April 2024(123)
- March 2024(112)
- February 2024(109)
- January 2024(95)
- December 2023(56)
- November 2023(86)
- October 2023(97)
- September 2023(89)
- August 2023(101)
- July 2023(104)
- June 2023(113)
- May 2023(103)
- April 2023(93)
- March 2023(129)
- February 2023(77)
- January 2023(91)
- December 2022(90)
- November 2022(125)
- October 2022(117)
- September 2022(137)
- August 2022(119)
- July 2022(99)
- June 2022(128)
- May 2022(112)
- April 2022(108)
- March 2022(121)
- February 2022(93)
- January 2022(110)
- December 2021(92)
- November 2021(107)
- October 2021(101)
- September 2021(81)
- August 2021(74)
- July 2021(78)
- June 2021(92)
- May 2021(67)
- April 2021(79)
- March 2021(79)
- February 2021(58)
- January 2021(55)
- December 2020(56)
- November 2020(59)
- October 2020(78)
- September 2020(72)
- August 2020(64)
- July 2020(71)
- June 2020(74)
- May 2020(50)
- April 2020(71)
- March 2020(71)
- February 2020(58)
- January 2020(62)
- December 2019(57)
- November 2019(64)
- October 2019(25)
- September 2019(24)
- August 2019(14)
- July 2019(23)
- June 2019(54)
- May 2019(82)
- April 2019(76)
- March 2019(71)
- February 2019(67)
- January 2019(75)
- December 2018(44)
- November 2018(47)
- October 2018(74)
- September 2018(54)
- August 2018(61)
- July 2018(72)
- June 2018(62)
- May 2018(62)
- April 2018(73)
- March 2018(76)
- February 2018(8)
- January 2018(7)
- December 2017(6)
- November 2017(8)
- October 2017(3)
- September 2017(4)
- August 2017(4)
- July 2017(2)
- June 2017(5)
- May 2017(6)
- April 2017(11)
- March 2017(8)
- February 2017(16)
- January 2017(10)
- December 2016(12)
- November 2016(20)
- October 2016(7)
- September 2016(102)
- August 2016(168)
- July 2016(141)
- June 2016(149)
- May 2016(117)
- April 2016(59)
- March 2016(85)
- February 2016(153)
- December 2015(150)
